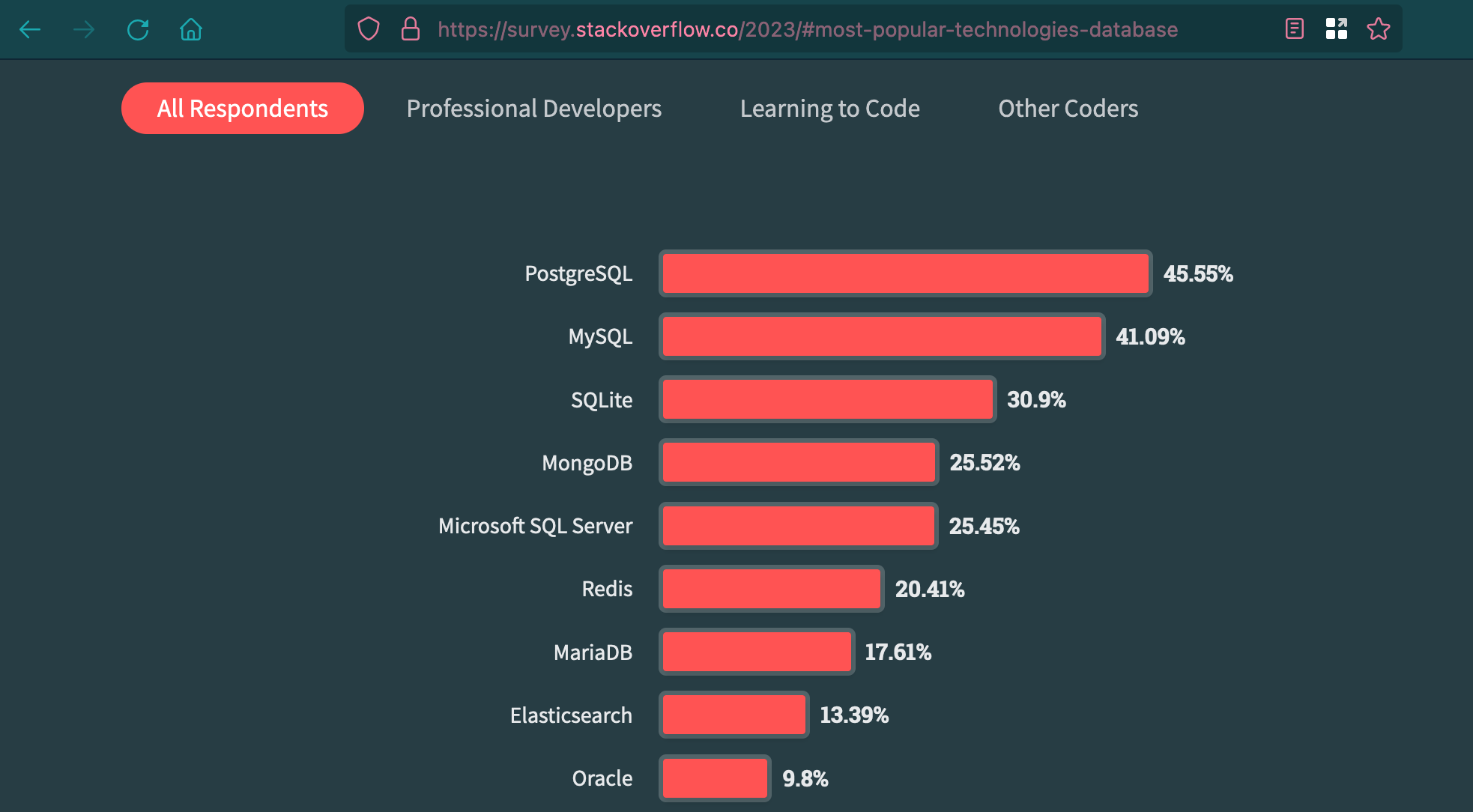
I have been interested into backend since college and I have admired PostgreSQL as a database since the beginning. I realised why I would use it over other offerings (mostly MySQL because as a student I could not afford any commercial ones anyway) and did not look back much. I have been coding backends for food since at least 10 years now and am biased towards PostgreSQL to an extent that it is the only SQL Database that I use in my projects. I am comfortable with its speed, feature-set, license, release-cycle etc. Maybe I am just way too accustomed to all of it. By the way, PostgreSQL just took over MySQL as the most preferred database for Professional Developers and so heavily, that the number actually outweighs every other database in All Respondents category as well.
Let’s take a moment to salute the hard work done by PostgreSQL developers around the world who have worked tirelessly to keep the “Most Advanced Open Source RDBMS” tag for at least 13 years that I have been using this database. If anything it shows how sheer technological improvements outweighs pure popularity which MySQL has boasted about for ages.
So whatever I am going to say here is about PostgreSQL only but might apply to other databases as well (by changing the methods and data types accordingly). Also, a disclaimer - this is my setup. This is what I prefer to do. It might not be perfect. What you want and prefer to do might be totally different. Depending on your database of choice and expertise, you might be able to have a different (maybe even better) setup.
Now, let’s start with the typical problems.
The problems (and the hints to solutions)
The standard problem of timestamps
Whether starting off a new project or trying to work with an existing one, there are certain things that keep coming back. For example, in most (if not all) cases you are going to need a primary key for each table. Pretty often we need to know when an entry was created (for example, when did a User register, when was an order placed, when was a blog post created etc.) and quite often when the entry was last updated (etc. when was a blog post last updated, when did the user last update his profile info etc.).
So we need those information in the database. So what do we need to store? We need to store the date and the time. Between the data type TIMESTAMP (TIMESTAMP WITHOUT TIME ZONE) and TIMESTAMPZ (TIMESTAMP WITH TIME ZONE) I prefer the one without Timezone; I like to store all times in UTC and convert them to whatever the user’s local time is with the frontend doing the timestamp conversions. It is scalable too if your app is going to be used across multiple timezones.
The coolest and the sexiest MVC Framework every built - Ruby on Rails comes with batteries included and if you generate a model using the standard CLI tools given by Rails, you get the columns created_at and updated_at by default in every table. So it has become a standard practice and the column names have also solidified themselves across different frameworks in different languages. So yeah, we should create those, totally!
The language we were using was not Ruby and we needed to write code for almost every table that we created. If you do not have a proper structure in place, you might have to start writing SQL statements that update the updated_at column all the time too. That’s cumbersome!
Needing to create more columns
We were releasing a new version of one of our services and we needed a database change (a new column in a table) for the feature to work. This service usually receives a large number of requests and the table which needed to be altered is an extremely busy one. Normally any ALTER TABLE would run without problems. But because of the way DB locks work, the migration could not run. We later calculated deterministically that the ALTER TABLE statement would never be able to acquire the lock (ACCESS EXCLUSIVE) needed for the change. We eventually had to pickup a time when the traffic was relatively lower and then bring down all services that depended on that table and then run the migration. It was painful.
It is in such conditions, that you wish you had one column which could be used to temporarily hold any kind of data so that you could deal with a super busy table at a much later time with proper warnings to users about scheduled downtime and still be able to push certain features or hotfixes immediately. JSON/JSONB data type comes up as a natural fit for such use-cases!
Still standing or Gone With the Wind? Doesn’t matter
The iconic novel derives its name from a poem and the words are uttered by the lead female character wondering if her plantation is still there or not. Regardless, the point I want to drive home is about the nature of data sitting in a DB. It is prone to be deleted; intentionally or accidentally someone might call DELETE on a row and you won’t be able to figure out if it ever existed (of course, there can be constraints to prevent that but it is still possible)!
However, many times we do need a log of such occurrences - for example if we need to perform audits on the table.
Also, previously we encountered the updated_at column. That column can say when the data was last changed without telling what was changed - which can be pretty important.
So we need some kind of a history table. The ideal way would be to have a corresponding history table for each table. e.g. a posts table could have a posts_history table. The history table could have the same schema as the main table but one where the primary key columns of the main table do not have the uniqueness constraint - so that you can store multiple versions of the same row in the history table.
But if you have 100s of tables, you know it would mean having another 100s of table for storing the history! So far that’s okay. The point where it starts getting messy is - what happens when you need to alter the columns in the main table? You would need to create the corresponding column in history table too! What happens if you drop a column from the main table? Do you drop the column from history table too and delete the data? Wouldn’t that defeat the purpose of the history table? What about maintaining the relevance of each table’s history (e.g. if you want to delete any “updates” for entries in certain history tables between a date range)?
You see? This design has got a lot of problems. We need something more generic, smaller and easier to maintain and understand too. Maybe we can have one audit_log table which records the changes for all tables concerned with a few other details.
The solution, the setup
When I create a new DB, especially for a new project, I always create one table named key_value table. It gives me a place to test anything (connectivity, permissions etc.) immediately and acts as a default table for storing anything random at any stage of the project. I sometimes also use it to store parts of configuration which need to be stored in the database. It is usually defined like below and we will be using this table as our test-bed for the rest of this post. Also, of course you can add indexes, constraints keys and whatnot to that table but for the sake of brevity we are going to skip all that.
CREATE TABLE IF NOT EXISTS key_value
(
key VARCHAR(512) PRIMARY KEY,
value TEXT NOT NULL,
created_at TIMESTAMP NOT NULL DEFAULT (NOW() AT TIME ZONE ('utc')),
updated_at TIMESTAMP NOT NULL DEFAULT (NOW() AT TIME ZONE ('utc')),
more_data JSONB NOT NULL DEFAULT '{}'::JSONB
);NOTE: I don’t like NULL values and try to keep things NOT NULL wherever possible.
Problem of timestamps
You can already see that I have set each row to have the default values for created_at and updated_at - both are UTC timestamp for the time of the row insertion. Fair and square.
Now, if you are going to use a table like this in your codebase, you can’t rely on the application to reliably update the updated_at field - what if the programmer forgets to do it in code? It should be done by the database for all updates, as it is done for insertion. For that we need to write a function and use it as a trigger for the update event.
---------------- FUNCTION TO UPDATE updated_at ----------------
CREATE OR REPLACE FUNCTION update_updated_at_task()
RETURNS TRIGGER AS
$$
BEGIN
NEW.updated_at = (NOW() AT TIME ZONE ('utc'));
RETURN NEW;
END;
$$ LANGUAGE 'plpgsql';This function can be used on any table with a updated_at with Timestamp data type. But this function alone cannot be used to update the values. We also need to create a trigger:
----- ATTACH THE TRIGGER TO TABLES -----
CREATE TRIGGER update_updated_at
BEFORE UPDATE
ON key_value
FOR EACH ROW
EXECUTE PROCEDURE update_updated_at_task();Creating this trigger will cause the function update_updated_at_task to be run right before any row in the key_value table gets updated and that NEW row will be actually saved to disk with the UTC timezone at the time (when the function runs) in the updated_at field.
Need to create more columns
So I have already told you about the problem we faced with having to modify a super-busy table in our database. Long story short, we ended up pushing the release timeline for that feature for almost a month and when the need became more than what would have justified the delay, we had to find a time-window when the load was minimal, then shut down all the services accessing that table and then we had to make the change. If only, we had a JSON/JSONB column readily available, we could have found a way to put the value in the JSON column and proceeded with the release.
JSONB is binary format for JSON data in PostgreSQL and allows you to store data in arbitrary structure (as long as it is valid JSON) and it is great for indexing and querying over it while JSON data type acts like a text field with basic JSON formatting checks put on top. The great thing is that PostgreSQL comes with a lot of JSON data type goodies. You can not only CRUD whole JSON documents, you can also do those operations on nested values inside the JSON documents. The best thing - you can write checks, constraints and indexes on individual fields inside your JSON/JSONB and treat those values almost like regular columns in their own right, if need be!
So if you someday need to insert a new piece of data in your column but the database is not free enough that you can just run an ALTER TABLE, having a JSON/JSONB column comes in handy. You can put all your data as a JSONB field and later adjust data into another column when you find the time while retaining the ability to work with the data as you would with a regular column all along.
The more_data field of this setup serves that same purpose - it allows you to put in arbitrary data and circumvents the need to create a new column right away! It allows you to take some time. It also allows you to have freehand over introducing a temporary or experimental column without having to actually change the core table structure.
Capturing the objects in wind
Now the other question - How do we preserve the history of certain tables. As you might have guessed, we are also going to do that using DB Triggers. But this one’s a little bit tricky (I assure you - it is only a little tricky). So the first thing to do is to create a table for saving all the history. I am going to call it audit_log because that is one of the biggest reasons why you would have such a table - to audit what happened to your database.
So let’s create the table first. Here is the SQL:
-- Table Definition
CREATE TABLE IF NOT EXISTS audit_log
(
"id" BIGSERIAL PRIMARY KEY,
"activity_timestamp" TIMESTAMP WITHOUT TIME ZONE DEFAULT (NOW() AT TIME ZONE 'utc'::text) NOT NULL,
"object_type" CHARACTER VARYING(128) NOT NULL,
"activity_type" SMALLINT DEFAULT 0 NOT NULL,
"object_id" CHARACTER VARYING(512) NOT NULL,
"old_data" JSONB DEFAULT '{}'::jsonb NOT NULL,
"new_data" JSONB DEFAULT '{}'::jsonb NOT NULL,
"more_data" JSONB DEFAULT '{}'::jsonb NOT NULL
);
-- Table and column comments
COMMENT ON TABLE audit_log IS 'Audit Log of activities happening inside the system';
COMMENT ON COLUMN audit_log.id IS 'Primary Key, Autoincrements - it is like an activity ID';
COMMENT ON COLUMN audit_log.activity_timestamp IS 'UTC time when the activity happened';
COMMENT ON COLUMN audit_log.object_type IS 'The kind of thing on which the activity was done.';
COMMENT ON COLUMN audit_log.activity_type IS 'What kind of activity was done (CUD operation - Read operations wont be logged here) 1=Create/Insert, 2=Update, 3=Delete';
COMMENT ON COLUMN audit_log.object_id IS 'ID of the object on which the operation was done in text format';
COMMENT ON COLUMN audit_log.old_data IS 'Old data for update and delete operations';
COMMENT ON COLUMN audit_log.new_data IS 'New data for create and update operations';
COMMENT ON COLUMN audit_log.more_data IS 'Anything else that needs to be saved';The definition of the table along with the comments on it should be self explanatory. However, I would still like to explain why I am choosing JSONB as the data type for old_data and new_data columns. Before we do that, let me tell you why we have these two columns. What we are trying to record the changes in the database, across all tables. So the fundamental actions that we need to record are the changes done to the data. You can say a row in a table has changed when:
- A new entry/row is created in a table: In this case, there is no old data but there is new data (which is the data that was just inserted) to be recorded.
- An existing row is updated: In this case, is the old data which was there in the row before the update happened and then there is the new data which stays in the row after the update is complete.
- An existing row is deleted from the table: In this case, we have the old data (which we deleted) and obviously, there is no new data to be recorded.
So we do need both these columns and since a row can have any kind of structure, we need a data type which is capable of handling multiple types of data and multiple number of columns that might be present in the table whose changes we are trying to record in our old_data and new_data columns. The best one for the purpose is JSONB because it is flexible and very importantly - pretty well supported by the database itself!
So, we have the table done. Now what we need to do is to create the trigger function which would be able to log these changes in the audit_log table. Here it is:
CREATE OR REPLACE FUNCTION audit_logfunc_key_value() RETURNS trigger
LANGUAGE plpgsql
AS
$$
BEGIN
IF (TG_OP = 'INSERT') THEN
INSERT INTO audit_log (activity_timestamp, object_type, activity_type, object_id, old_data, new_data, more_data)
VALUES ((NOW() AT TIME ZONE ('utc')), 'key_value', 1, NEW.key, '{}'::JSONB, TO_JSONB(NEW), '{}'::jsonb);
RETURN NEW;
ELSIF (TG_OP = 'UPDATE') THEN
INSERT INTO audit_log (activity_timestamp, object_type, activity_type, object_id, old_data, new_data, more_data)
VALUES ((NOW() AT TIME ZONE ('utc')), 'key_value', 2, NEW.key, TO_JSONB(OLD), TO_JSONB(NEW), '{}'::jsonb);
RETURN NEW;
ELSIF (TG_OP = 'DELETE') THEN
INSERT INTO audit_log (activity_timestamp, object_type, activity_type, object_id, old_data, new_data, more_data)
VALUES ((NOW() AT TIME ZONE ('utc')), 'key_value', 3, OLD.key, TO_JSONB(OLD), '{}'::JSONB, '{}'::jsonb);
RETURN OLD;
END IF;
END
$$;You can already see what is happening in the function audit_logfunc_key_value above. We are inserting a row in the audit_log table for every INSERT, UPDATE or DELETE operation that it receives. The object_type here is key_value which is the name of the table for which function will be triggered (using a trigger attached to the table, described a little below), the activity_type being what we wrote in the comment on the activity_type column and the values for old_data and new_data set to the old and new values received by this trigger function where the blank values are represented by an empty JSON object.
NOTE: Notice that I am returning OLD for the DELETE operation because once the deletion is done, the NEW value won’t be present.
And again we need the trigger:
CREATE TRIGGER z_audit_log
BEFORE INSERT OR DELETE OR UPDATE
ON key_value
FOR EACH ROW
EXECUTE FUNCTION audit_logfunc_key_value();So every time, an INSERT, DELETE or UPDATE is performed on the table, a new corresponding row for each row changed is created in the audit_log table using the trigger we have defined just above.
Now there is an interesting thing that you might have noticed. I named my trigger z_audit_log. I could have just called it audit_log or audit_log_key_value or audit_log_trigger; so why did I attach a z_ to the beginning of the name? The reason for this is - we already have another trigger on the key_value table which is named as update_updated_at_task. If I were to name this new trigger any of the above options I just presented, it would be alphabetically before this other trigger.
Something to remember!
Triggers in PostgreSQL on the same table are executed in their alphabetical order. So in that case, this new trigger (which we have named
z_audit_log) would get executed before theupdate_updated_at_task(if it were named any of the above values) and that has an unwanted effect of updating theupdated_atvalue after logging the values inaudit_logtable and that makes the data look erroneous and inconsistent.
Conclusion
Every application is different and the database design for all those needs are going to be different. But one thing is constant in all applications (as it is with every other thing in the universe too): change. Everything needs change and applications need to adapt with the growing changes. A good base setup that solves some basic issues that you are going to face as you move forward while staying flexible when you really need is going to save you tons of time and effort as you move forward.
I have learnt that this setup works well because of those hardships. I hope it saves some for you and lets you discover other and hopefully better problems.